








 English
English
 繁體中文
繁體中文
 Deutsch
Deutsch
 Français
Français
 Español
Español
 日本語
日本語
 Tiếng Việt
Tiếng Việt
 Português
Português
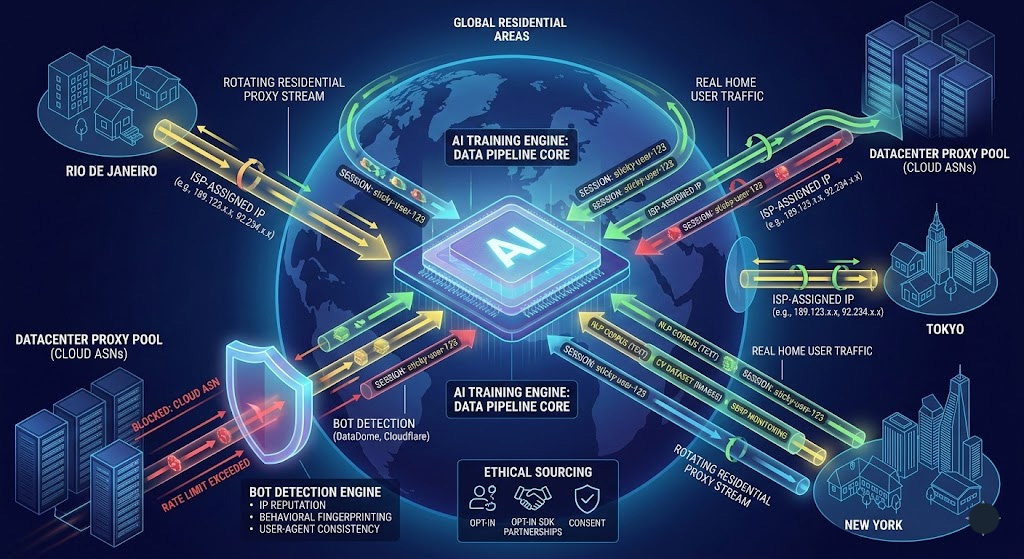
GPT-3's pre-training dataset drew 410 billion tokens from Common Crawl alone—about 60% of the model's weighted training mix, filtered down from roughly 45TB of raw crawled text. That number gets cited constantly. What rarely gets mentioned is the infrastructure that makes collecting data at that scale possible without getting blocked after the first few thousand requests.
Residential proxies are a big part of that story. For teams building real AI pipelines, they're often the difference between a scraper that works and one that's dead by Tuesday morning.
Why Large-Scale AI Data Collection Is Harder Than It Sounds
Publicly available web data is, technically, publicly accessible. Operationally, not so much.
Modern websites layer bot detection and rate limiting that has gotten harder to navigate every year—CAPTCHA challenges, IP reputation scoring, behavioral fingerprinting. When you're collecting millions of documents to train an NLP model or tens of thousands of images to fine-tune a vision system, automated traffic patterns get flagged even when the use case is entirely legitimate.
DataDome's detection engine processes 5 trillion signals per day across its customer network—client-side and server-side data points feeding ML models that build behavioral profiles at a cross-site level, not just per-domain. At scale, a vanilla Python scraper hitting the same site from the same IP block will get banned within hours.
Beyond rate limiting, there's the geographic problem. A model trained on US-centric web text has real performance gaps in other languages and markets. Geo-restricted content, localized search results, and region-specific pricing pages simply aren't accessible from a single data center IP in Virginia.
Common Crawl is an excellent resource and genuinely underused—but it's a snapshot, not a live feed. It can be months out of date, doesn't cover many high-value domains at sufficient depth, and tells you nothing about real-time content like news, social media, or product listings.
What Makes a Residential Proxy Different?
A residential proxy routes your requests through an IP address assigned by a real ISP to a real residential location. From the target website's perspective, the request looks like it's coming from an ordinary home internet user in, say, São Paulo or Stuttgart.
That's meaningfully different from a datacenter proxy, which routes through IPs registered to commercial hosting providers—AWS, DigitalOcean, OVH. Websites' bot detection systems have spent years fingerprinting those ranges; many block entire ASNs associated with cloud providers by default.
ISP proxies are a middle ground: ISP-assigned addresses housed on data center hardware. They're faster and more stable than residential IPs but easier to bulk-fingerprint once a provider's ASN gets flagged. The practical choice between proxy types comes down to your target's detection sophistication.
Residential vs. Datacenter Proxies: Which One Does AI Data Collection Actually Need?
The honest answer: it depends on the target.
Datacenter proxies are fast, inexpensive, and work fine against targets with minimal bot detection—public APIs, lightly protected content feeds, domains that don't fingerprint IP reputation aggressively. For a few hundred requests per domain per day, they're sufficient and significantly cheaper per GB.
Residential proxies are the right tool when:
Target sites cross-reference IP reputation against datacenter ASNs.
You need geographic diversity in training data.
Session continuity matters.
Your collection runs at scale long-term.
Rotating residential proxies—where each request or session gets a different IP from the pool—are the standard configuration for most AI data pipelines.
How AI Teams Actually Use Residential Proxies
NLP and LLM corpus collection
High-volume domain-specific scraping (legal, regional news, forums). Rotating + geo-targeting ensures multilingual and localized coverage.
Computer vision dataset construction
Large-scale image scraping from e-commerce or archives without rate-limit bans.
Sentiment analysis and market intelligence
Geo-targeted access to real regional user-generated content.
SERP monitoring for LLM evaluation
Search engines are heavily protected; residential proxies are effectively required.
The Detection Arms Race: What Happens When Websites Fight Back
Residential proxies aren't invisible.
Detection systems analyze behavioral signals:
Cross-site browsing patterns
User-agent inconsistencies
Session depth and timing
Cloudflare and DataDome both rely heavily on behavioral scoring rather than just IP blocking.
Practical mitigation strategies:
Randomized crawl delays (2–5s, non-uniform)
Consistent user-agent per session
Sticky sessions for workflows
The Ethics Question Nobody Asks: Where Do These IPs Come From?
Residential proxy IPs come from real users via:
SDK integrations (bandwidth sharing)
ISP agreements
Peer networks
Risk assessment:
Red flags
No disclosure of sourcing
No opt-out mechanism
No compliance documentation
Green flags
Public SDK/peer documentation
Clear opt-in flow
GDPR compliance + DPA availability
This is not theoretical—this is supply chain compliance risk.
When You Don't Actually Need Residential Proxies
Avoid using them when:
Official API exists
Common Crawl / datasets suffice
Low request volume (< few thousand/day)
In these cases, proxies add cost + risk without upside.
How to Set Up a Residential Proxy (5-Minute Start)
Prerequisites
Python 3.8+
requests library
Step 1 — Credentials
Get:
host
port
username
password
Step 2 — Basic rotating request
import requests
proxies = {
"http": "http://USERNAME:PASSWORD@PROXY_HOST:PORT",
"https": "http://USERNAME:PASSWORD@PROXY_HOST:PORT",
}
response = requests.get("https://httpbin.org/ip", proxies=proxies, timeout=10)
print(response.json())Step 3 — Sticky session
import uuid, requests
session_id = uuid.uuid4().hex[:8]
proxies = {
"http": f"http://USERNAME-session-{session_id}:PASSWORD@PROXY_HOST:PORT",
"https": f"http://USERNAME-session-{session_id}:PASSWORD@PROXY_HOST:PORT",
}
r1 = requests.get("https://httpbin.org/ip", proxies=proxies)
r2 = requests.get("https://httpbin.org/ip", proxies=proxies)
print(r1.json(), r2.json())Troubleshooting
ProxyError → host/port wrong
407 → auth issue
Real IP returned → proxies dict misconfigured
Compliance Note
Check robots.txt
Review ToS
Proxy ≠ permission
Next Steps
Production requires:
Playwright / Selenium(JS rendering)
Scrapy crawl delay control
Session lifecycle management
Start Collecting Without the Blocks
Residential proxies enable:
geo diversity
long-term scraping stability
lower block rates
Test with real targets before scaling.
