








 English
English
 繁體中文
繁體中文
 Deutsch
Deutsch
 Français
Français
 Español
Español
 日本語
日本語
 Tiếng Việt
Tiếng Việt
 Português
Português
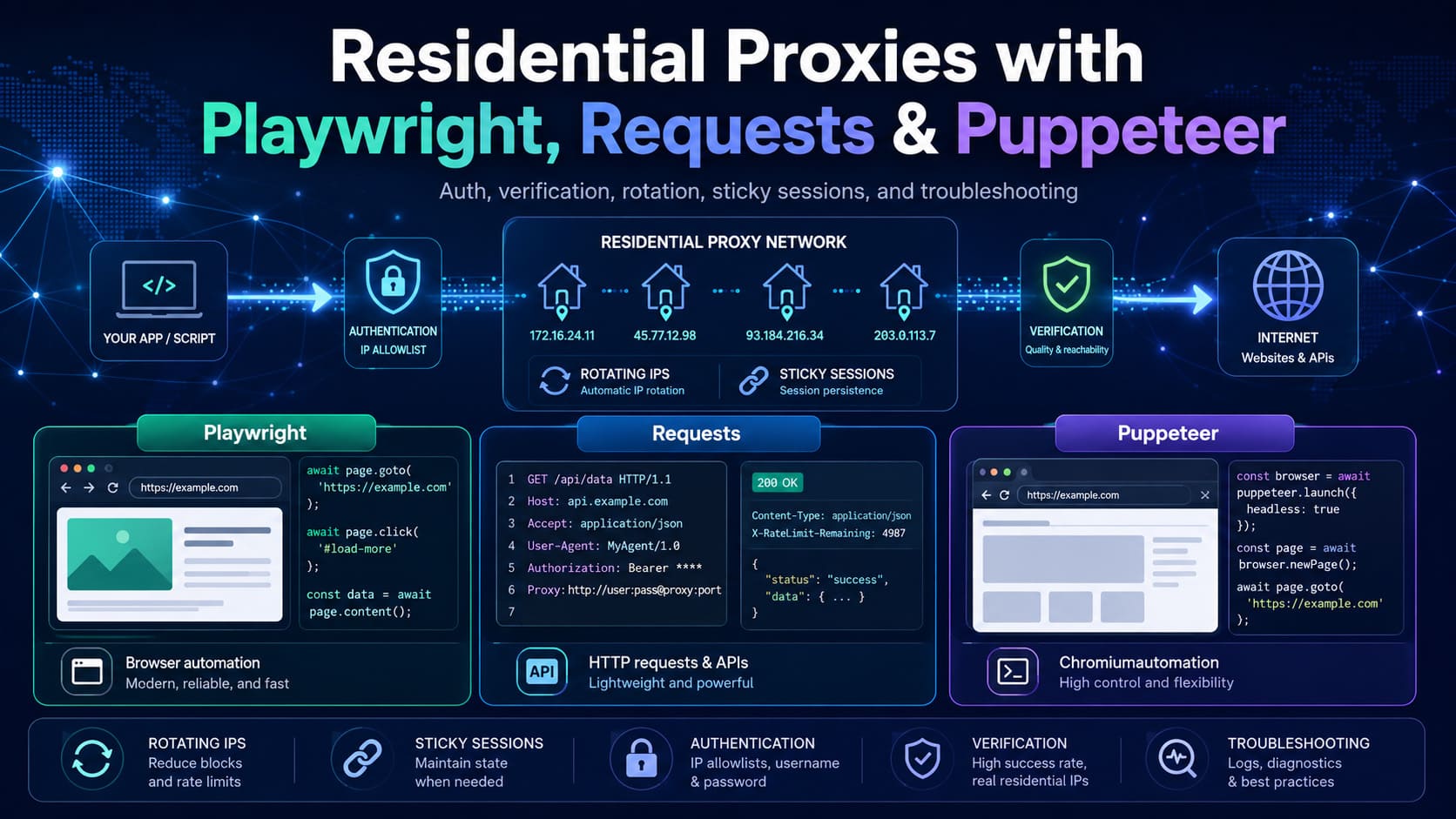
How to Use Residential Proxies With Playwright, Requests, and Puppeteer
Residential proxies work differently across Playwright, Requests, and Puppeteer because each library attaches proxy settings at a different layer of the stack. Playwright applies proxy settings at browser launch, Requests uses a proxy mapping in the HTTP client layer, and Puppeteer typically passes the proxy through Chromium launch arguments and then handles authentication on the page.
That difference decides your implementation pattern. If you need full browser execution for JavaScript-heavy pages, Playwright or Puppeteer is usually the right fit. If you only need direct HTTP calls, Requests is simpler and easier to rotate per request or per session.
This article focuses on the part that matters in production: how to wire residential proxies correctly, how to verify that traffic is actually leaving through the proxy, and how to keep session behavior predictable when you need either rotation or continuity.
Which tool fits best?
Use Requests when the target workflow is pure HTTP and you don’t need a real browser engine. Requests sessions persist parameters across requests, while Playwright and Puppeteer proxy the browser’s network traffic instead of a lightweight client call path.
Use Playwright when you want browser automation with first-class proxy support in the launch configuration. Its browser launch API supports both HTTP and SOCKS proxies, and the proxy setting is used for all requests from that browser instance.
Use Puppeteer when your automation stack is already Chromium-centered and you want the familiar --proxy-server model. In Puppeteer, the common pattern is to launch Chromium with the proxy server argument and then pass credentials with page.authenticate() before loading the target page.
There’s also an operational difference between rotating and sticky behavior. Residential providers often expose rotation and session controls on the provider side, while the code in these libraries mainly decides where and how the proxy is attached in your client or browser session.
This is the right decision point for provider selection. If you need provider-side rotation, IP whitelisting, sub-user management, and usage visibility, Proxy001’s residential product page publicly presents those capabilities, which aligns well with the workflows in this guide.
Shared setup
Before you paste any code, gather four values from your proxy provider dashboard or API docs: proxy host, proxy port, username, and password. If your provider supports country targeting or sticky sessions, retrieve those controls from the provider’s endpoint format or session settings instead of guessing the syntax in code.
You also need a clean verification target. A simple IP-check page is enough for first validation because it lets you confirm that the outbound IP changes when you expect rotation and stays stable when you expect session continuity.
Use one rule across all three libraries: verify the proxy before you point it at a real workload. That gives you a fast way to separate “proxy wiring is wrong” from “the target site is behaving differently.”
The common prerequisites are:
A residential proxy endpoint that supports the protocol your library will use, usually HTTP or SOCKS for Playwright and HTTP proxy syntax for typical Puppeteer launch flows.
Clear credentials, either embedded in the library’s proxy object or passed through the browser authentication step, depending on the library.
A decision on session behavior, because rotating traffic and sticky flows should not be validated the same way.
Three failure patterns show up first in real setups:
The browser launches, but traffic still goes out directly because the proxy was attached in the wrong place or the scheme was wrong.
Authentication fails because credentials were put into the wrong field, such as trying to treat Playwright exactly like Puppeteer or vice versa.
Rotation seems “broken” even though the provider is actually keeping the same session alive by design.
Keep the compliance boundary clear from the start. Residential proxies are appropriate for approved workflows such as regional QA, ad verification, localized content validation, data-quality testing, fraud analysis, and authorized research. They should not be used as instructions for defeating access controls or bypassing a site’s terms.
How to use residential proxies with Playwright
Playwright’s proxy support is built into browser launch, which makes it the cleanest of the three for browser-level routing. The key point is that the proxy is configured on launch and applies to all requests from that browser instance.
Here’s a minimal Playwright Python example with a residential proxy:
from playwright.sync_api import sync_playwright
PROXY_SERVER = "http://YOUR_PROXY_HOST:YOUR_PROXY_PORT"
PROXY_USERNAME = "YOUR_USERNAME"
PROXY_PASSWORD = "YOUR_PASSWORD"
VERIFY_URL = "https://httpbin.org/ip"
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={
"server": PROXY_SERVER,
"username": PROXY_USERNAME,
"password": PROXY_PASSWORD,
},
)
page = browser.new_page()
page.goto(VERIFY_URL)
print(page.text_content("body"))
browser.close()This pattern matches Playwright’s documented proxy object, which accepts a server value and supports authenticated HTTP or SOCKS proxy usage at launch. If your provider issues SOCKS residential endpoints, change the scheme to socks5:// instead of forcing HTTP syntax.
Use Playwright when you want one browser session to stay internally consistent. That makes it a good fit for flows like logged-in QA, multi-step localization checks, or browser-based data validation where the same browser session should keep one routing policy throughout the run.
Verify Playwright in two passes. First, confirm that the IP-check page shows a proxied address. Second, relaunch a fresh browser session and see whether the provider returns a different IP for rotating traffic or preserves continuity for a sticky configuration.
The most common Playwright mistakes are straightforward:
Putting the credentials into a raw URL string when the launch
proxyobject is the cleaner documented path.Assuming a new page changes the proxy when the proxy is attached to the launched browser instance.
Debugging the target site first instead of validating against an IP-check endpoint.
How to use residential proxies with Requests
Requests is the simplest option when you don’t need a browser. It’s a better fit for APIs, HTML fetches, or verification tasks where JavaScript rendering is unnecessary and the overhead of a full browser would just slow the workflow down.
A clean Requests setup uses a proxies mapping and, for repeated work, a Session. Requests’ advanced usage documentation covers sessions and proxy-related configuration, and Sessions are useful because they persist parameters across calls instead of making you rebuild every request from scratch.
Here’s a minimal Requests example:
import requests
PROXY_URL = "http://YOUR_USERNAME:YOUR_PASSWORD@YOUR_PROXY_HOST:YOUR_PROXY_PORT"
VERIFY_URL = "https://httpbin.org/ip"
session = requests.Session()
proxies = {
"http": PROXY_URL,
"https": PROXY_URL,
}
response = session.get(VERIFY_URL, proxies=proxies, timeout=30)
print(response.text)This pattern is easy to reason about because the proxy is visible right on the request path. It also makes Requests the easiest of the three libraries for per-request routing if you want different proxy endpoints or different session tokens across separate HTTP calls.
There is one detail worth keeping in mind: Requests does not time out by default, so you should set a timeout explicitly in real use instead of letting failed proxy connections hang indefinitely. The docs also describe advanced session behavior, which is why a Session is the right default once you move beyond one-off tests.
Verify Requests the same way you verify Playwright: hit an IP-check endpoint first and inspect the returned IP before you use the session against a target workflow. If the IP doesn’t change when you expected rotation, check the provider’s session policy before you start rewriting the client code, because rotation often depends on the provider-side session model, not on Requests itself.
The top Requests troubleshooting items are:
The
httpandhttpskeys do not both point to the intended proxy endpoint.The credentials are malformed in the proxy URL.
The request appears “stuck” because no timeout was set.
How to use residential proxies with Puppeteer
Puppeteer handles proxies at the Chromium layer rather than through a dedicated high-level proxy object like Playwright. The usual pattern is to pass the proxy server through --proxy-server and then authenticate the page before navigation.
Here’s a minimal Puppeteer example:
import puppeteer from "puppeteer";
const PROXY_SERVER = "http://YOUR_PROXY_HOST:YOUR_PROXY_PORT";
const PROXY_USERNAME = "YOUR_USERNAME";
const PROXY_PASSWORD = "YOUR_PASSWORD";
const VERIFY_URL = "https://httpbin.org/ip";
const browser = await puppeteer.launch({
headless: true,
args: [`--proxy-server=${PROXY_SERVER}`],
});
const page = await browser.newPage();
await page.authenticate({
username: PROXY_USERNAME,
password: PROXY_PASSWORD,
});
await page.goto(VERIFY_URL, { waitUntil: "networkidle2" });
console.log(await page.content());
await browser.close();This matches the standard documented pattern shown in current Puppeteer proxy guides: set --proxy-server at launch, then call page.authenticate() when your proxy requires credentials. That also means Puppeteer setups often fail for a very specific reason: the browser launches correctly, but the proxy auth step never happens or happens after the wrong page flow starts.
Puppeteer is a strong fit when your automation is already built around Chromium and you want a direct, explicit browser-argument model. Operationally, though, it behaves more like Playwright than Requests because the proxy choice belongs to the browser session, not to a lightweight HTTP call path.
Verify Puppeteer the same way as the other two libraries. Visit an IP-check endpoint first, confirm that the browser is really exiting through the residential proxy, and only then move to a real task or workflow.
A few fixes solve most Puppeteer proxy problems:
If the page loads without proxy auth, confirm that
page.authenticate()runs before the page navigation that needs the proxy.If the IP-check result does not match expectations, inspect the exact
--proxy-servervalue for scheme and host formatting.If rotation is inconsistent, check whether the provider is assigning sticky session behavior by default.
The practical takeaway is simple. Requests is the fastest route for direct HTTP work, Playwright is the cleanest browser-level integration, and Puppeteer is the familiar Chromium-centric option when your stack already lives there.
For teams that want to move from examples to production, the provider side matters as much as the client code. Proxy001’s residential offering is a sensible starting point for this setup because its public product page lists rotating residential support, IP whitelisting, sub-user management, and usage monitoring—features that make Playwright, Requests, and Puppeteer setups easier to validate and operate once you move beyond one-off tests.
