








 English
English
 繁體中文
繁體中文
 Deutsch
Deutsch
 Français
Français
 Español
Español
 日本語
日本語
 Tiếng Việt
Tiếng Việt
 Português
Português
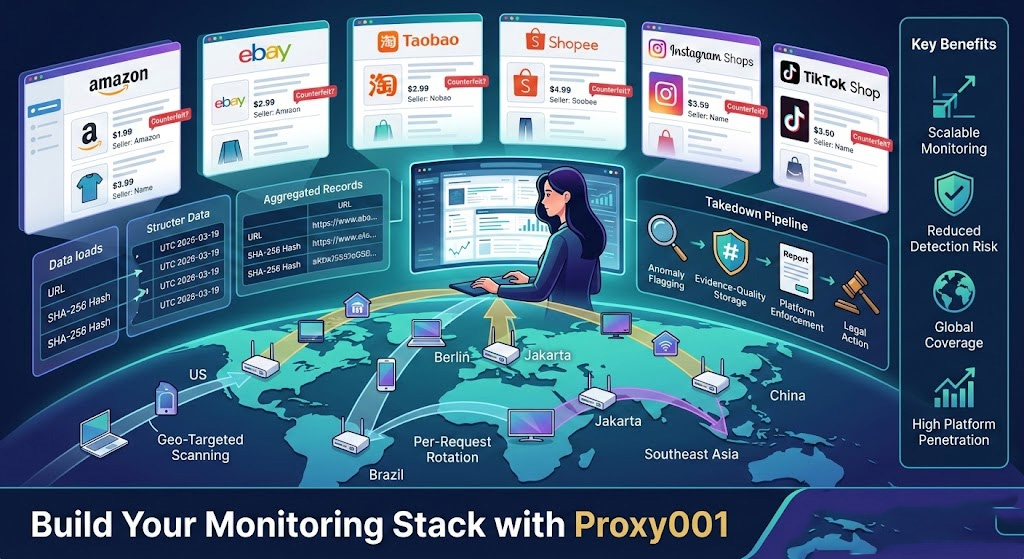
A brand analyst searching Amazon for her company's premium skincare line finds 47 listings she doesn't recognize—same product photos, suspiciously lower prices, different seller names. She flags them manually. A week later, 12 more appear. Three months in, she's running the same search daily, barely keeping up with the US store, and hasn't touched Taobao, Tokopedia, or the dozen Instagram shops pushing the same knockoffs in Brazil.
Manual monitoring doesn't scale. More importantly, it doesn't give you the full picture. Platforms return different results depending on where you're browsing from, and if the platform's anti-bot system identifies your corporate IP doing repeated brand searches, it starts serving filtered content rather than what a regular consumer in Berlin or Jakarta actually sees. That's where residential proxies change the equation.
This guide walks through how residential proxies work for counterfeit monitoring, how to build an actual monitoring workflow, what it takes to turn scraped data into enforceable evidence, and how to evaluate a proxy provider for this specific use case.
Why Counterfeits Are Hard to Catch Without the Right Infrastructure
Counterfeit goods don't live in one place. The distribution map spans:
Tier-1 marketplaces: Amazon, eBay, Walmart Marketplace—where counterfeiters list under generic seller names, rotate product identifiers, and piggyback on legitimate brand listings
Regional marketplaces: Taobao, Alibaba, Tokopedia, Shopee, Lazada—where much of the manufacturing-adjacent counterfeit supply originates and where most US-based brand teams have zero visibility
Social commerce: Instagram Shops, TikTok Shop, Facebook Marketplace—where individual sellers operate in gray zones with minimal platform verification
Standalone counterfeit sites: Exact-replica storefronts with slight domain variations (brandname-official.com, brand-name-store.net) that run paid ads and surface in organic search
B2B wholesale platforms: DHgate, Made-in-China—where counterfeit goods are sold in bulk under OEM framing
The core problem isn't just volume—it's geographic fragmentation. The same search on Amazon.com from a US IP returns completely different listings than from a Polish IP or a Singapore IP. Sellers targeting Southeast Asian consumers don't bother optimizing for US search visibility, and geo-restricted promotions hide entire segments of infringing activity from US-based monitoring teams.
Add anti-bot protections: if a monitoring tool hits a marketplace repeatedly from a recognized datacenter IP range, the platform starts throttling, serving CAPTCHAs, or showing sanitized results. At that point, you're not monitoring the platform—you're monitoring what the platform wants you to see.
Why Do Brand Teams Use Residential Proxies Instead of Datacenter Proxies?
Datacenter proxies fail for counterfeit monitoring for one straightforward reason: their IP ranges are publicly catalogued. Every major e-commerce platform maintains blocklists of known datacenter IP blocks—AWS, GCP, Azure, and colocation facilities all have well-documented IP ranges—and applies heightened scrutiny or outright blocks to traffic from those addresses. Residential proxies route requests through IP addresses assigned by real ISPs to real home connections, so to the destination platform, the request looks identical to a consumer browsing from that city. There's no datacenter fingerprint to match against.
That distinction matters most on platforms with aggressive bot scoring. Because residential IPs route through actual consumer connections, platforms that score traffic by IP reputation treat them as organic activity. Datacenter IPs don't pass that check. In testing against several tier-1 and regional marketplace platforms in early 2026, rotating residential proxies sustained usable response rates across extended overnight scan windows on targets where datacenter IPs hit blocks or CAPTCHA walls within the first few hundred requests. The performance gap is most pronounced on regional Asian marketplaces—Taobao, Shopee, and Tokopedia all apply fingerprinting that's calibrated specifically against datacenter traffic patterns.
ISP proxies sit in the middle: technically registered to ISPs, making them appear more legitimate than pure datacenter IPs, but hosted in datacenter infrastructure. They're faster than residential proxies and harder to detect than standard datacenter ranges. For monitoring workflows where speed matters and target platforms are moderately protected, they're viable. For heavily protected platforms—social commerce scrapers, regional Asian marketplaces—residential proxies remain the more reliable choice.
The tradeoff is cost and latency. Residential proxies cost more per GB and introduce delay because requests go through a real home connection. For monitoring, that's generally acceptable—counterfeit monitoring is a batch workload, not a real-time application, and a 2–3 second response delay per request doesn't matter when scans run overnight.
What Happens When You Monitor Counterfeits Without Geo-Targeting?
Counterfeit operations are often geographically segmented. A seller running knockoffs may only target consumers in Southeast Asia and Western Europe—US-based scans won't surface those listings at all. Some counterfeiters actively suppress visibility in regions where the authentic brand has strong enforcement presence. Monitoring from a single US IP isn't global coverage; it's one slice of one market.
Geo-targeting in residential proxies means requesting IPs from specific countries, states, or cities so that your traffic originates from those locations. A monitoring sweep checking the same product keywords from US, German, Brazilian, Thai, and Australian IPs will surface significantly more infringing listings than a US-only scan. The exact syntax to specify a target country varies by provider—some encode it in the proxy username (e.g., user-country-DE:password@host:port), others use a separate hostname per region or a query parameter in the proxy URL. Check your provider's geographic targeting documentation before building scan jobs; getting this format wrong is the most common setup mistake, and the failure is silent—you'll get responses, but from the wrong region.
The practical setup is a set of parallel scan jobs, one per target region, running against each priority marketplace in sequence. Results get merged and deduplicated in post-processing. For a scan job making 500–1,000 requests across a few hours, a pool with at least a few hundred IPs in the target country prevents the same address reappearing frequently enough to trigger anomaly detection. This is where residential proxies with unlimited bandwidth or high-volume plans pay off—running parallel regional jobs adds up fast.
Social media proxies deserve specific mention here. Instagram and TikTok apply aggressive rate limiting and geo-based content filtering to automated traffic. Running residential proxies matched to the region you're scanning isn't optional on those platforms—it's the minimum viable approach to getting consistent, representative results.
The End-to-End Monitoring Workflow: From Scrape to Evidence
With the proxy layer and geo targets defined, the actual monitoring workflow runs in four stages. The technical decisions at each stage determine whether the output is usable for enforcement or just raw data.
Stage 1: Configure the proxy layer
Before writing any scraping logic, you need a working residential proxy setup that handles authentication and rotation. The skeleton below is the minimum foundation—it handles a single authenticated request through a rotating endpoint. Extend it with a real parser, task queue, and storage layer before running at scale.
pythonimport requestsimport hashlibfrom datetime import datetime, timezone# Prerequisites:# - Python 3.8+# - pip install requests# - A residential proxy account with rotating endpoint access# (Retrieve endpoint URL, port, and credentials from your provider's dashboard)PROXY_USER = "your_username"PROXY_PASS = "your_password"PROXY_HOST = "rotating.your-provider.com" # From your provider's dashboardPROXY_PORT = "10000" # From your provider's dashboard# Geo-targeting syntax varies by provider.# Some append it to the username: "user-country-US"# Others use a separate endpoint or URL parameter.# Confirm the exact format in your provider's API documentation.proxies = { "http": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}", "https": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}",}def fetch_listing(url: str) -> dict: # Use a standard browser User-Agent to ensure compatibility with # platforms that require it for proper content delivery. # Retrieve your provider's recommended request header configuration # from their documentation — some providers supply pre-configured # header sets optimized for specific target platforms. headers = { "User-Agent": "YOUR_USER_AGENT_HERE", # From your proxy provider's docs "Accept-Language": "en-US,en;q=0.9", } try: resp = requests.get(url, proxies=proxies, headers=headers, timeout=30) resp.raise_for_status() return { "url": url, "fetched_at_utc": datetime.now(timezone.utc).isoformat(), "status_code": resp.status_code, "content_hash": hashlib.sha256(resp.content).hexdigest(), "response_size_bytes": len(resp.content), "html": resp.text, } except requests.RequestException as e: return { "url": url, "error": str(e), "fetched_at_utc": datetime.now(timezone.utc).isoformat(), }Standard request headers ensure your monitoring tool receives the same page content a browser would. Your proxy provider's documentation typically specifies which headers to use for each target platform.
For production: wrap this in a task queue (Celery or RQ), add per-domain rate limiting, and implement exponential backoff on failures. The rotating endpoint handles IP rotation automatically—you don't need to manage individual IPs.
Stage 2: Define your scanning scope
Cover the following per marketplace per scan job:
Branded keyword searches: brand name alone, brand + product category, common misspellings and transliterations
Exact product identifiers where applicable: UPC, EAN, model number strings
Visual counterfeit detection (counterfeits that avoid brand keywords entirely) requires a separate implementation path from keyword-based monitoring—each platform handles image search differently, and automating it means working with that platform's specific form submission structure or image search API. If visual similarity matching is a priority, treat it as a distinct track and build it after your keyword pipeline is stable.
Set frequency by platform velocity: Tier-1 marketplaces (Amazon, eBay) update listings continuously—daily scans are warranted. Regional marketplaces can run weekly. Standalone counterfeit sites can run on a 72-hour cycle unless you're in active enforcement against a specific seller.
Stage 3: Evidence-quality storage
Raw HTML dumps are not evidence. Every record your system stores needs:
Full URL of the infringing listing (not a search results page)
UTC timestamp of fetch (not local time—UTC is unambiguous in cross-jurisdiction enforcement)
SHA-256 hash of the raw HTML at capture time
Full-page screenshot with URL bar visible
Structured fields: seller name, price, listing title, product image URLs
The content hash is what separates monitoring data from evidence capture. If a seller modifies or removes a listing after you file a report, your hash proves what that page contained at a specific time.
Stage 4: Anomaly flagging
Build a flagging layer rather than manually reviewing thousands of records:
New seller IDs matching brand keywords first seen in the last 48 hours
Price differential threshold (e.g., more than 40% below your MAP policy price)
Duplicate product images appearing on non-authorized seller pages (requires perceptual hashing with a library like
imagehash)
This collapses the daily review queue to the actionable subset.
Verify your setup is working:
Run a test request, then call the ipinfo.io API with the exit IP to confirm it's a residential address in your target region
Confirm the content hash changes between consecutive runs on a known dynamic page—this verifies that IP rotation is active and you're not receiving cached responses through a sticky session
Run a test scan against one of your highest-priority marketplaces and check for consistent 200 responses without CAPTCHA challenges; if you're getting blocked, address it before building the broader pipeline
Top 3 issues that break setups:
Compliance note before you deploy at scale: Confirm your target platforms' Terms of Service don't explicitly prohibit automated data collection for brand protection purposes. Most major marketplaces distinguish between abusive high-volume scraping and IP enforcement monitoring—but ToS language varies and your legal team should review each platform. Also confirm that your stored data doesn't inadvertently capture personally identifiable information (seller profile pages on some platforms include name and contact details), which brings GDPR and CCPA into scope. The full legal framework is in the compliance section below; don't skip it before going live.
What Makes Monitoring Data Usable as Legal Evidence?
There's a real gap between "we detected these listings" and "here is evidence that can support a takedown or legal action." That gap lives in documentation quality.
For platform takedown filings—Amazon's Brand Registry Report a Violation tool, eBay's VeRO program, Shopify's trademark complaint process—you typically need:
The exact URL of the infringing listing
Screenshots with the URL bar visible and a clear timestamp
Your trademark or copyright registration number
A specific statement of how the listing infringes (counterfeit goods, unauthorized trademark use, copyright infringement of product imagery)
Amazon's system may require a test purchase to confirm the physical product is counterfeit before actioning certain reports. If that's requested, document the purchase with side-by-side photos of the counterfeit packaging and your authentic product—that documentation becomes part of your evidence record.
For DMCA notices, the requirements are more formal: a signed declaration (under penalty of perjury) identifying the copyrighted work, the URL of the infringing material, and your contact information. DMCA applies specifically to copyright claims—product photos, marketing copy, registered brand imagery. Trademark and patent infringement go through separate channels and don't use DMCA notices; conflating them is a common mistake that results in rejected filings.
For civil litigation, evidence standards are higher. Screenshots need a verifiable chain of custody: captured by an automated system with NTP-synchronized timestamps, hashed at capture time, stored in a tamper-evident system. Specialized tools like Page Vault are built specifically for court-admissible web evidence collection. The SHA-256 hashes from Stage 3 of the monitoring workflow feed directly into this chain of custody.
The enforcement escalation path, ordered by severity and resource investment:
Platform's native IP reporting tool — fast, no cost, covers most cases on major marketplaces; appropriate for the bulk of infringing listings
DMCA notice — for copyright-specific claims; formal but platform-agnostic; use when the infringing content includes your registered images or copy
Trademark infringement letter from legal counsel — for persistent sellers who survive platform-level reporting; the letter creates a documented record before litigation
Civil litigation — reserved for high-volume, high-value infringers; requires significantly more documented evidence and scales up the cost accordingly
Choosing a Residential Proxy Provider: 5 Criteria That Matter for Brand Monitoring
Generic proxy selection advice doesn't map well to counterfeit monitoring requirements. Five criteria actually matter for this use case:
1. Geographic coverage depth
You need coverage beyond the US and Western Europe. Counterfeit hotspots in Southeast Asia, Eastern Europe, and Latin America require IP pools with genuine residential coverage in those regions—not a token handful of IPs. Ask specifically about IP count in your target countries, not just total pool size.
2. Rotation flexibility
Counterfeit monitoring requires per-request rotation to avoid triggering rate limits on marketplace platforms. Per-session rotation (where the same IP persists through a session) isn't sufficient for batch scan workloads. Confirm the provider supports per-request rotation for scan jobs and sticky sessions separately for any login-required pages.
3. Bandwidth model
A system running 24/7 across multiple regions consumes significant bandwidth. Pay-per-GB models work well for initial testing; for production monitoring, look at providers offering residential proxies with unlimited bandwidth or high-volume plans that eliminate cost unpredictability at scale.
4. Protocol compatibility
Most enterprise scraping stacks (Scrapy, Playwright, Puppeteer, Selenium) support both HTTP CONNECT tunneling and SOCKS5. Confirm your provider supports the protocol your stack uses before signing up.
5. Trial availability
Counterfeit monitoring requires validating that the proxy layer actually penetrates your specific target platforms before committing spend. A provider without a trial makes that pre-commitment validation impossible. Test against your top-priority marketplaces specifically—don't rely on general claims about success rates.
Proxy001 covers these criteria: 100M+ residential IPs across 200+ regions, both HTTP and SOCKS5 protocol support, per-request rotation and sticky session modes, and native SDK integration for Python, Node.js, Puppeteer, and Selenium. Their free trial lets you test penetration on your actual target platforms before any meaningful spend. For a brand team that needs to validate coverage in Southeast Asian or Eastern European markets, that trial period gives you real-world penetration data before you commit to a scraping architecture—run it against your highest-priority marketplaces and measure actual success rates, not vendor claims.
When Is a Residential Proxy Not Enough?
Residential proxies are infrastructure. They solve the detection and geo-targeting problem—they don't solve the analysis, classification, or enforcement problem. Five scenarios hit that ceiling hard.
Closed-app environments: Counterfeits sold through WeChat Mini Programs, private Telegram channels, or WhatsApp-based seller networks aren't accessible to any web scraper because the content lives behind authenticated, app-based interfaces. No proxy type gets you past this.
Visual counterfeit detection: Identifying that a product image is a visual copy of your authentic product requires perceptual hashing, CNN-based similarity scoring, or reverse image search at scale. That's a separate system sitting above the data collection layer—residential proxies deliver the raw content, but detecting visual similarity is a computer vision problem.
Low-volume precision sellers: A sophisticated counterfeiter moving high-value inventory in small quantities, deliberately avoiding brand-name keywords, and using subtly different product descriptions won't surface reliably through keyword-based scraping. This requires investigative work that automation doesn't replace.
Real-time enforcement is a different problem category. When a takedown needs to happen within hours—around a product launch or a high-profile event—you need human operators and platform relationships, not a detection pipeline. Detection latency of 24–48 hours is fine for ongoing monitoring; it's not fine for rapid-response situations. Similarly, counterfeit goods traded through dark web marketplaces or private reseller communities require approaches that go well beyond automated monitoring entirely.
For brands dealing with significant counterfeiting volume in these harder channels, the right architecture is residential proxies combined with a specialized brand protection platform—Corsearch, BrandShield, and Tracer all offer AI-assisted detection and enforcement support that goes beyond what a proxy-based monitoring layer can do alone. Residential proxies are typically part of those platforms' own infrastructure anyway, and running your own monitoring layer alongside them gives you faster scan cycles and lower-cost coverage for the channels you've already mapped.
Is Using Residential Proxies for Counterfeit Monitoring Legal?
Scraping publicly accessible product listings for brand protection purposes is generally legal in the United States, with real caveats that your legal team should review before deploying at scale.
In hiQ Labs v. LinkedIn, the Ninth Circuit affirmed in April 2022 that scraping publicly accessible data likely does not constitute "unauthorized access" under the Computer Fraud and Abuse Act—the federal statute that would make scraping a criminal matter. The court held that the CFAA's "without authorization" requirement doesn't apply to data that's publicly visible without a login. That ruling held up after a Supreme Court remand and remains the leading US precedent for this question.
Three caveats matter for brand monitoring specifically.
ToS violations are a contract issue, not a criminal one. The hiQ ruling didn't eliminate breach of contract claims. If a marketplace's terms of service prohibit automated scraping, violating those terms can expose you to contract liability. In practice, most major platforms distinguish between abusive high-volume scraping and brand protection monitoring—but your legal team should review the specific ToS for each platform before deploying.
Data protection law applies when personal data is in scope. GDPR and CCPA govern the collection of identifiable personal data. For counterfeit monitoring, your collected data is typically product listings, pricing, and seller IDs—not personal data. But if your scraper captures seller profile pages containing names or contact details, that changes the analysis under GDPR. Design your data collection scope to avoid capturing personal data you don't need.
Jurisdiction matters beyond the US. hiQ is Ninth Circuit precedent—it applies in the US. The EU has distinct legal frameworks, including database rights under the EU Database Directive, that can complicate mass extraction from EU-hosted platforms. If you're running scans against EU-based marketplaces and storing the results, consult local counsel on the specific data extraction questions.
The practical principle: use monitoring data for enforcement and evidence purposes only, not for republication or secondary commercial use. Document your monitoring methodology and data retention practices so you can demonstrate the data was collected specifically for brand protection if it's ever challenged.
The framework above covers the full loop: proxy infrastructure, geo-targeted scanning, evidence-quality data capture, and a clear enforcement escalation path. A brand team with this in place moves from reactive whack-a-mole to systematic intelligence—detecting infringing listings before they accumulate, building evidence records that support platform takedowns and legal action, and maintaining visibility across the regional markets where counterfeit supply actually originates.
Three next steps to start this week:
List the five platforms where you've spotted—or suspect—the most infringing activity. That becomes your scanning priority list and determines your required proxy coverage regions.
Map which of those platforms need geo-targeted scanning. Regional marketplaces (Taobao, Shopee, Tokopedia) and social commerce in non-US markets are non-negotiable for geo-targeting; start there.
Test your proxy layer against those specific platforms before building the full pipeline. Platform penetration varies, and you need real data before committing to a scraping architecture.
Build Your Monitoring Stack with Proxy001
Running counterfeit monitoring at scale means running constant, multi-region scans against platforms that actively filter automated traffic. That requires a residential proxy network with genuine geographic depth—not just headline IP numbers, but real coverage in the Southeast Asian and Eastern European markets where counterfeit supply is heaviest.
Proxy001 gives brand and legal teams 100M+ residential IPs across 200+ regions, with per-request rotation, HTTP and SOCKS5 support, and ready-to-use SDK integrations for Python, Node.js, Puppeteer, and Selenium. The same infrastructure that powers web scraping and price tracking works directly for brand monitoring workflows—no specialized setup required.
Start with the free trial before committing to a plan. Test penetration against your specific target marketplaces, validate your geo-targeting configuration in the regions that matter for your brand, and confirm your success rates on the platforms where counterfeit exposure is highest. Visit proxy001.com to request your free trial and run the first scan.
