








 English
English
 繁體中文
繁體中文
 Deutsch
Deutsch
 Français
Français
 Español
Español
 日本語
日本語
 Tiếng Việt
Tiếng Việt
 Português
Português
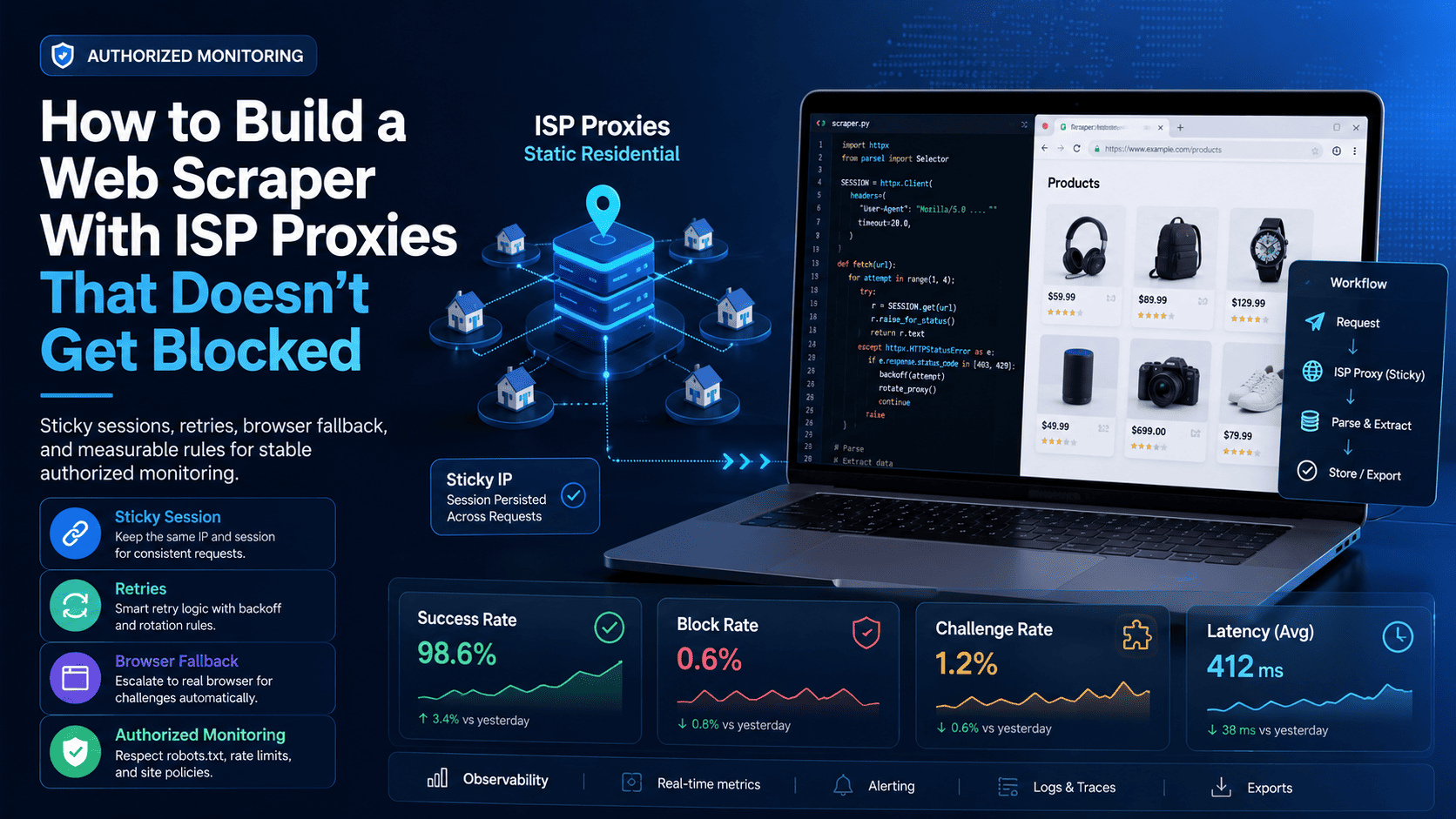
What "stable" means, and when ISP proxies fit
A stable scraper is one that can complete a permitted batch of work with predictable success, acceptable latency, and a low rate of deny pages, 429 responses, or challenge pages that interrupt the workflow. If you don't log those outcomes, you can't tell whether your architecture is working or whether it only succeeded briefly by chance.
Start by tracking four metrics on every run:
Success rate: the share of requests that return the page or payload you expected.
Block rate: the share of requests that return 403, 429, 503, or an obvious deny response.
Challenge rate: the share of responses that return a human-verification page instead of usable content.
Median response time: how long successful requests take through the current proxy path.
ISP proxies fit best when your workflow needs a stable session across multiple requests rather than constant IP churn. Static residential proxies, often described as ISP proxies, keep one ISP-assigned IP for longer-lived use, which makes them a practical fit for account continuity, browser-driven QA, or location-sensitive verification flows.
A rotating residential proxy network fits better when you need broad coverage across many pages, categories, or regions, while datacenter proxies are still useful for simpler and lower-risk workloads but are easier to classify at the network level. A simple rule works well in practice: use ISP proxies for stateful steps, use residential proxies for broad discovery, and use a real browser when the page depends on client-side rendering.
Anti-bot systems also look far beyond IP type. Cloudflare's documentation explicitly describes JA3/JA4 fingerprinting, signals intelligence, and behavioral analysis, which is why a better IP alone doesn't fix an unstable client or an overly aggressive request pattern. In other words, the right proxy helps, but session handling, cookies, transport behavior, and request pressure still decide whether your monitoring stack stays reliable.
Architecture and credential mapping
A workable ISP-proxy scraper needs a queue, a scheduler, a session-aware proxy manager, and a metrics layer. The simplest clean architecture is one worker per sticky ISP IP, one cookie jar per worker, one small batch per run, and a logger that records status codes, response timing, and challenge pages for every request.
That design matters because a static IP is a session resource, not an unlimited pipe. Overusing one sticky IP for unrelated jobs creates noisy behavior in your own logs and makes it harder to tell whether a failure came from the endpoint, the client, or the workload design.
Before you write code, confirm five fields from your provider dashboard:
Proxy host.
Proxy port.
Username.
Password.
Whether the endpoint is for static/sticky ISP use or a rotating residential pool.
If you're using Proxy001 for the example workflow, use its static residential product rather than the rotating residential pool when you want one sticky ISP session, since the product page describes dedicated ISP IPs, 30-day terms, region-based options, and per-IP pricing for that use case. Copy those credentials into your scraper exactly as host, port, username, and password, then verify the outbound IP before you touch a real target.
One important clarification: the numeric values in the sample code below are conservative starter defaults for testing and observability, not universal thresholds. Tune them against your own logs rather than treating them as fixed industry limits.
HTTP path for server-rendered pages
If the content you need is already present in the initial HTML or a simple API response, start with requests.Session rather than a browser. Requests supports persistent sessions, cookies, explicit proxies, and timeout handling, which is enough for many server-rendered monitoring tasks.
Install the minimum dependencies:
python -m pip install requests beautifulsoup4
Create one sticky session per ISP IP:
import time
import random
from dataclasses import dataclass
from urllib.parse import quote
from requests import Session
from requests.adapters import HTTPAdapter
from urllib3.util import Retry
from bs4 import BeautifulSoup
@dataclass
class ProxyConfig:
host: str
port: int
username: str
password: str
def as_requests_proxies(self):
user = quote(self.username, safe="")
pwd = quote(self.password, safe="")
proxy_url = f"http://{user}:{pwd}@{self.host}:{self.port}"
return {"http": proxy_url, "https": proxy_url}
def build_session():
session = Session()
session.headers.update({
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Connection": "keep-alive",
})
retries = Retry(
total=3, # starter default, tune from logs
backoff_factor=1.0, # starter default, tune from logs
status_forcelist=[429, 500, 502, 503, 504],
allowed_methods=frozenset(["GET", "HEAD"])
)
adapter = HTTPAdapter(max_retries=retries)
session.mount("http://", adapter)
session.mount("https://", adapter)
return sessionThis design follows the documented strengths of Requests sessions: cookies persist across requests and connections can be reused, which is exactly what a stateful session needs. Requests also does not apply timeouts unless you set them explicitly, so every outbound call should define connect and read limits.
Verify the endpoint before scraping:
def verify_ip(session, proxies): r = session.get( "https://httpbin.org/ip", proxies=proxies, timeout=(5, 20) # starter default ) r.raise_for_status() return r.json()
Using an IP-check URL first catches the most common setup errors: wrong endpoint, wrong credentials, and credentials that were not URL-encoded correctly inside the proxy URL. It also gives you a clean audit point in your run log before the scraper touches any monitored site.
Fetch one low-risk page and classify the response:
def classify_response(response): text = response.text.lower() if response.status_code in (403, 429): return "blocked" if "captcha" in text or "verify you are human" in text: return "challenge" if response.status_code == 503: return "temporary_unavailable" if response.status_code >= 500: return "server_error" return "ok" def fetch_page(session, url, proxies): r = session.get( url, proxies=proxies, timeout=(5, 30), # starter default allow_redirects=True ) return r, classify_response(r) def extract_title(html): soup = BeautifulSoup(html, "html.parser") return soup.title.get_text(strip=True) if soup.title else None
Keep the first runs deliberately small:
def polite_sleep(min_seconds=2.0, max_seconds=5.0):
time.sleep(random.uniform(min_seconds, max_seconds))
def run_job(proxy_cfg, target_urls):
session = build_session()
proxies = proxy_cfg.as_requests_proxies()
print("Outbound IP:", verify_ip(session, proxies))
results = []
for idx, url in enumerate(target_urls, start=1):
r, label = fetch_page(session, url, proxies)
title = extract_title(r.text) if label == "ok" else None
results.append({
"url": url,
"status_code": r.status_code,
"label": label,
"elapsed_seconds": round(r.elapsed.total_seconds(), 2),
"title": title,
})
if idx < len(target_urls):
polite_sleep()
return resultsThe point of the first batch is observability, not scale. Run one worker on one ISP IP, keep one cookie jar tied to that worker, and review the result before you add more concurrency. Scale only after several low-volume runs stay stable in your own logs.
Add a simple run summary:
from collections import Counter
from datetime import datetime
def summarize(results):
counts = Counter(item["label"] for item in results)
total = len(results)
return {
"timestamp_utc": datetime.utcnow().isoformat(),
"total_requests": total,
"ok": counts.get("ok", 0),
"blocked": counts.get("blocked", 0),
"challenge": counts.get("challenge", 0),
"temporary_unavailable": counts.get("temporary_unavailable", 0),
"server_error": counts.get("server_error", 0),
"success_rate": round(counts.get("ok", 0) / total, 3) if total else 0,
"block_rate": round(counts.get("blocked", 0) / total, 3) if total else 0,
"challenge_rate": round(counts.get("challenge", 0) / total, 3) if total else 0,
}Use three practical checks before moving on:
The IP verification endpoint shows the proxy's outbound IP.
The monitored page returns expected content instead of a deny or challenge page.
Several small runs in a row show stable success and latency before you raise volume.
If you hit problems early, the fix path is usually simple:
407 Proxy Authentication Required: re-check the endpoint, product type, and URL-encoded credentials.Hanging workers: add explicit timeouts to every request.
Clean verification but unstable page fetches: confirm that the page is actually server-rendered before spending time on more HTTP-only tuning.
Browser path for JavaScript-heavy pages
If the content appears only after the browser runs JavaScript, keep the same ISP session model and switch the client to Playwright. Playwright's Python documentation supports authenticated HTTP(S) proxies directly through the proxy launch option, including server, username, and password.
Install Playwright and Chromium:
python -m pip install playwright playwright install chromium
Create one browser context per sticky ISP session:
from playwright.sync_api import sync_playwright
PROXY = {
"server": "http://YOUR_PROXY_HOST:YOUR_PROXY_PORT",
"username": "YOUR_USERNAME",
"password": "YOUR_PASSWORD",
}
TARGET_URL = "https://YOUR-ALLOWED-JS-TARGET/page"
with sync_playwright() as p:
browser = p.chromium.launch(headless=True, proxy=PROXY)
context = browser.new_context(
locale="en-US",
user_agent=(
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/124.0.0.0 Safari/537.36"
)
)
page = context.new_page()
page.goto(TARGET_URL, wait_until="domcontentloaded", timeout=30000)
page.wait_for_load_state("networkidle")
title = page.title()
html = page.content()
print({"title": title, "html_length": len(html)})
context.close()
browser.close()That is the safest dividing line in practice: if the page requires a browser runtime, use a browser runtime instead of trying to stretch an HTTP client into something it isn't. Playwright also exposes network inspection hooks, which helps when the data appears through XHR or fetch after the initial HTML load.
Your verification standard stays the same:
The page loads through the ISP proxy.
The rendered content you actually need appears.
Multiple low-volume runs remain stable before you expand the workload.
Diagnostics, compliance, and rollout
When a run becomes unstable, diagnose the failure before you change the whole stack. A jump in 503 responses may point to temporary origin issues, while 403 and 429 responses usually indicate a policy or rate problem, so those categories should be logged separately. If one region degrades while another still works, compare the same workflow across two regions before concluding that your scraper logic is broken.
A clean diagnostic order looks like this:
Verify the endpoint and outbound IP again.
Confirm whether the page is server-rendered or JavaScript-rendered.
Re-run one worker on one ISP IP with a small batch.
Review cookies, status codes, challenge pages, and latency together rather than in isolation.
Expand only after repeated low-volume runs stay consistent.
Use the same caution with scope. Google's robots guidance explains that robots.txt is used to manage crawler traffic and avoid unnecessary load, which makes it a practical first checkpoint for any monitoring or scraping workflow. It is not the only rule that matters, so also review the site's Terms of Service, stay on public or explicitly authorized pages, avoid personal data, and keep request volume low enough that your own activity does not stress the service.
A good final operating rule is to separate session-critical monitoring from broad collection workloads. That separation improves observability, preserves cleaner logs, and makes it easier to tell whether a failure came from the endpoint, the client, or the job design. If you need both sticky ISP sessions and a large residential proxy network under one roof, Proxy001 is a reasonable product fit to test because its public pages document both a static residential ISP offering and a larger residential network with 100M+ IPs across 200+ regions.
If you need a practical starting point, begin with a very small sticky ISP pool, bind one worker to one IP, log every run, and validate the workflow before you scale. Proxy001 publishes static residential ISP options with dedicated IPs and a broader residential network for teams that later need a hybrid monitoring stack, so it's a sensible place to run that first proof of concept on an authorized workload.
