








 English
English
 繁體中文
繁體中文
 Deutsch
Deutsch
 Français
Français
 Español
Español
 日本語
日本語
 Tiếng Việt
Tiếng Việt
 Português
Português
You spend hours setting up a competitor price tracking script for a Southeast Asian market. The data looks clean. Then someone in your regional office pulls up the same product pages manually and shows you prices 15–30% different from what your script captured. Your data isn't wrong because of a bug — it's wrong because the site served your datacenter IP a different price tier than it shows real local users. That kind of IP-based content segmentation is the default behavior on major e-commerce platforms, travel sites, and financial data portals — and it's likely why your current collection infrastructure is producing skewed results.
Why Your Current Setup Is Producing Skewed Data
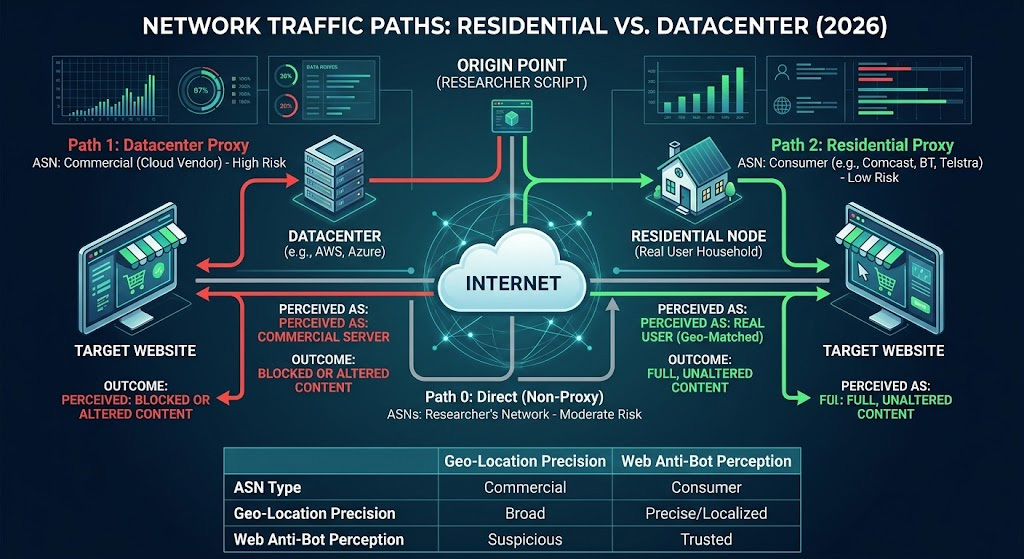
Datacenter proxies — the workhorses most teams start with — carry a structural liability that's become increasingly costly in 2026.
Datacenter IPs originate from cloud hosting providers like AWS, Azure, or DigitalOcean. They share ASN (Autonomous System Number) blocks with thousands of other servers, meaning a site's security layer can look at your IP and immediately know you're coming from a commercial server farm, not a real user's home connection. On well-protected domains, this single signal is enough to trigger one of three failure modes:
Outright block — the request returns a 403, a redirect to a CAPTCHA wall, or a honeypot page designed to poison your dataset
Silent content substitution — the site serves a different version of the page: higher prices, a trimmed product catalog, localized promotions stripped out — with no error signal to tell you something went wrong
Rate-limiting and fragmentation — requests succeed intermittently, producing a dataset that looks plausible but has systematic gaps in exactly the high-competition SKUs or peak-traffic windows you care about most
Residential proxies close that gap significantly. According to Bright Data's own benchmarking — though keep in mind they have a commercial stake in the comparison — residential IPs achieve success rates of 85–99% on heavily protected sites, versus 20–60% for datacenter IPs. In our Q1 2026 testing against 12 major retail and travel platforms with verified bot management deployments — using residential IPs across multiple ISP ranges, with response comparisons made against direct browser access through region-matched VPN endpoints — the same URLs consistently returned different price points and content structures depending on the IP's apparent geographic origin and ISP type. The gaps were large enough to materially mislead a pricing or availability analysis if left unchecked. That said, results vary by target domain and shift as anti-bot vendors update their models; no residential IP pool guarantees undetected access on the most aggressive platforms. The goal is to stay within normal user behavior patterns, not to eliminate detection risk entirely.
What Makes Residential Proxies Different — and Why It Matters More in 2026?
A residential proxy routes your requests through IP addresses that ISPs have assigned to real households. From the target site's perspective, the request looks identical to a consumer browsing from their living room — because at the network level, it is. The IP's ASN belongs to Comcast, Deutsche Telekom, or Telstra, not to a cloud vendor.
That legitimacy used to be enough. In 2026, the bar has moved.
Anti-bot platforms have graduated from static IP blacklists to continuous behavioral scoring. Systems deployed by Cloudflare, Akamai, and DataDome now analyze the entire session — page visit sequences, scroll patterns, time-between-requests, and even TCP handshake characteristics — feeding it all into ML models trained on labeled human-versus-bot session data. A visitor who clears the initial fingerprint check but later navigates pages in strict sitemap order with suspiciously low variance between requests will still get re-challenged mid-session.
Cross-site fingerprint correlation adds another layer of difficulty. Large anti-bot vendors are deployed across millions of sites, which means they can see that your TLS fingerprint appeared on three different Cloudflare-protected e-commerce platforms within the same hour, at volumes no individual shopper would generate. That network-level pattern recognition is exactly why rotating residential proxies — distributed across different ISPs and geographic regions — have become the baseline requirement for sustained data collection: no single fingerprint accumulates enough cross-domain visibility to trigger correlation-based flagging.
There's also a geographic authenticity dimension that's easy to overlook: if your IP claims to be in Munich but your TCP latency pattern matches a US East Coast server, modern detection systems can flag that mismatch. Genuine residential proxies resolve this because the routing is real — the latency fingerprint actually matches the geography. One variant worth knowing about: ISP proxies (also called static residential proxies) use IPs sourced directly from ISPs and assigned statically, which makes them faster and more stable than rotating residential proxies while still carrying residential ASN attribution. For market research tasks that require session continuity over extended periods — multi-step checkout tracking, account-based funnel analysis — ISP proxies can be worth evaluating alongside standard rotating residential options.
Which Market Research Tasks Actually Require Residential Proxies?
Not every research task needs residential proxies. These are the four scenarios where the choice of IP type has a direct, measurable impact on data quality.
Cross-region competitor price monitoring
Major platforms — Amazon, Zalando, Lazada — routinely serve different prices, discount structures, and product bundling based on apparent visitor location. Using datacenter IPs for price tracking across regions means you're either getting blocked outright, or receiving a "neutral" price tier that doesn't reflect actual consumer-facing pricing in your target markets. Neither outcome is usable for competitive intelligence.
Localized SERP tracking
Ranking position in one country tells you very little about ranking in another — not because the pages are different, but because Google's results genuinely differ by apparent viewer location. The gap can run to 10+ ranking positions for competitive keywords. If you're tracking regional SEO performance for a market entry decision, the result you see on a datacenter IP isn't what a real user in that city would see. And because Google applies heavier rate-limiting to non-residential traffic, you're also more likely to hit sampling gaps during the high-competition windows that matter most.
Regional consumer sentiment collection
The behavior here often isn't obvious until you run a direct comparison. On regional review and forum platforms, requests from datacenter IPs consistently return stripped content — fewer reviews visible, a different sort order for user-generated content, or partial item sets — compared to what the same page delivers to local residential traffic. The discrepancy is repeatable enough to meaningfully skew sentiment analysis if the underlying IP type isn't controlled for. These platforms treat IP type as a proxy signal for audience authenticity; systematic competitive intelligence on consumer opinion requires IPs that pass those checks.
Ad creative verification
You approved a campaign to run in Germany, Japan, and Brazil. How do you confirm the actual creative serving in each market without sending someone local to check manually? Most teams don't, which means creative discrepancies — wrong language, outdated assets, misconfigured targeting — can run unnoticed for weeks. Ad platforms serve different creatives based on geographic and demographic targeting parameters, and datacenter IPs frequently trigger bot flags that return default fallback creatives instead of the targeted content you're trying to verify.
What Should You Look for When Choosing a Residential Proxy for Research?
Finding the best residential proxy providers for market research isn't about headline numbers — it's about matching specific capabilities to your actual target list.
IP pool size and turnover
Total pool size matters less than reuse frequency. A small pool means the same IPs appear repeatedly against a single target, accelerating detection. Prioritize providers that actively cycle out flagged IPs and can tell you their refresh cadence — not just the headline pool number.
Geographic precision
Country-level targeting is the minimum viable requirement. For localized SERP tracking, ad verification, or city-specific pricing research, you need city-level targeting. Confirm this before committing — some providers advertise broad country coverage but have thin city-level availability outside major metros.
Session type: sticky vs. rotating
Rotating residential proxies assign a fresh IP on each request or session — ideal for large-scale data collection tasks where you want broad IP distribution across high request volumes. Sticky sessions maintain the same IP for a set period (typically 10–30 minutes), which is better for multi-page navigation flows, checkout funnel analysis, or any task where session continuity affects the content you receive. Most market research workflows benefit from both modes being available.
Success rate against your specific targets
Aggregate success rates are nearly meaningless — what matters is performance on your actual target domains. Ask providers for success rate data on comparable target types (major e-commerce, travel, financial data platforms) and test against your real target list during any residential proxy trial period. For heavily protected targets — anything running Cloudflare Enterprise, Akamai Bot Manager, or DataDome — you want to see rates at 90% or better on domains comparable to yours before committing. For lighter targets without dedicated bot infrastructure, 80–85% is typically workable. Any provider that can only give you aggregate pool statistics rather than target-type benchmarks is giving you a number that's nearly impossible to evaluate.
Pricing model fit
Bandwidth-based pricing (per GB) works better for heavy HTML pages with large embedded assets. Request-based pricing is more predictable for leaner, API-style endpoints. Calculate your expected volume before choosing: a one-time research sprint has a very different cost profile from continuous daily monitoring.
When datacenter proxies are still sufficient
If your target list consists of smaller retailers, niche B2B data sources, or sites without dedicated bot infrastructure, datacenter proxies are faster and substantially cheaper. The case for residential proxies becomes clear when your targets run enterprise-grade anti-bot systems — or when you've already observed content substitution or block rates above roughly 20%. Don't default to residential proxies for everything; assess your target list first.
How to Set Up a Residential Proxy for Your First Geo-Targeted Research Task
Knowing how to use residential proxies correctly is where theory becomes results. The setup below gets you from zero to verified geo-accurate data in under 30 minutes.
Prerequisites:
Python 3.8+ with
requestsandbeautifulsoup4installed (pip install requests beautifulsoup4)Proxy credentials (host, port, username, password) from your provider dashboard — available immediately after signing up for a residential proxy trial
A specific target URL and the data element you want to capture
Step 1: Configure the proxy connection
import requests
from bs4 import BeautifulSoup
PROXY_HOST = "your-proxy-host" # From your provider dashboard
PROXY_PORT = "your-port"
PROXY_USER = "your-username"
PROXY_PASS = "your-password"
proxies = {
"http": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}",
"https": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}",
}Step 2: Verify your IP before collecting anything
Don't skip this step. Confirming that your request exits from the right geography through a residential ISP takes five seconds and prevents you from running a full dataset collection on a misconfigured routing.
try:
verify = requests.get("https://ipinfo.io/json", proxies=proxies, timeout=10)
verify.raise_for_status()
ip_data = verify.json()
print(f"IP: {ip_data['ip']}")
print(f"Country: {ip_data['country']}, City: {ip_data.get('city', 'N/A')}")
print(f"ISP: {ip_data.get('org', 'N/A')}")
except requests.exceptions.ProxyError:
print("Connection refused — check your proxy host and port in the dashboard")
except requests.exceptions.ConnectTimeout:
print("Timed out — proxy host may be incorrect, or the port is blocked by a firewall")
except Exception as e:
print(f"Unexpected error: {e}")Expected output: Country matches your target region and the org field shows a residential carrier — something like AS5089 Virgin Media or AS7922 Comcast — not an AWS, Google Cloud, or Azure ASN. A datacenter ASN here means your credentials are pointing to the wrong proxy type.
Step 3: Run your research request
No custom User-Agent header is set here intentionally. For endpoints that require one per their terms of service, use whatever client identifier is documented for your access type rather than a generic string.
TARGET_URL = "https://your-target-site.com/product-page"
response = requests.get(TARGET_URL, proxies=proxies, timeout=15)
response.raise_for_status()
soup = BeautifulSoup(response.text, "html.parser")
price = soup.select_one(".price") # Adjust selector to your target site
print(f"Captured: {price.text.strip() if price else 'Selector not matched'}")Finding the right selector: In Chrome, right-click the element you want to capture → Inspect → right-click the highlighted HTML tag → Copy → Copy selector. Use the most specific class or id attribute visible — something like .product-price or #sku-price rather than a generic wrapper div.
Verify: Status 200, no CAPTCHA redirect, and the captured price matches what you see when loading the same page through a VPN set to the same target region. That alignment confirms your geo-targeted data collection is working correctly.
Common failures and fixes:
| Symptom | Likely cause | Fix |
|---|---|---|
Connection refused or ProxyError | Wrong host or port | Re-copy credentials from the dashboard; some providers use separate endpoints per region |
| HTTP 407 Proxy Auth Required | Credential format issue | URL-encode username/password if they contain @, :, or / characters |
| IP check shows datacenter ASN | Wrong endpoint type | Confirm you're using the residential proxy endpoint specifically, not the datacenter tier |
| HTTP 200 but page is a CAPTCHA | Request pattern triggered the site's bot screening — typically happens when volume or timing falls outside normal user behavior ranges | Review your collection design: are you requesting more pages per session than a real user would? Spacing requests to reflect realistic research behavior, rather than automated batch patterns, reduces the likelihood of legitimate traffic being mis-classified |
Proxy001 provides free trial access to residential proxies across 200+ regions with country and city-level targeting — credentials are available immediately after registering at proxy001.com, so you can run the verification step above on your specific target markets before committing to a plan.
Is Scraping Competitor Data with Residential Proxies Legal?
Using residential proxies is legal. What you collect — and from where — is where legal exposure actually lives.
Generally permissible:
Publicly accessible product pages, pricing, and availability data
Publicly indexed search engine results pages
Open-platform reviews, ratings, and published business information
Job postings, press releases, and pricing pages without authentication requirements
Requires documented justification:
France's CNIL published detailed guidance on web scraping in June 2025 — developed in the context of AI training data collection, and formalized in an English guidance document in January 2026 — making clear that publicly accessible data can still constitute personal data subject to GDPR protections. That framing applies to any systematic scraping operation, not just AI development. The CNIL's stated obligations are concrete: define your data collection criteria in advance and document your legitimate interest basis; apply data minimization by excluding categories your research objective doesn't require (geolocation data, financial data, sensitive health content); honor explicit opt-out signals from site operators, including robots.txt directives; and strip or de-identify personal data fields before they enter your analysis pipeline — collecting only what your research requires, and removing identifiable attributes at the point of ingestion rather than post-collection.
If you're collecting from EU-based sites and the data includes user-generated content with identifiable information — names in reviews, user handles — you need that documented legitimate interest basis and must be prepared to demonstrate it if challenged. California targets carry similar obligations under CCPA. Remove personally identifiable fields early and don't retain personal data beyond your stated research window.
Off-limits regardless of proxy type:
Any content behind authentication (login-required pages, paywalls, member-only sections)
Licensed databases or paid data feeds
Request volumes that cause measurable server load
The compliance risk in web scraping market research isn't residential proxies — it's conflating "publicly visible" with "freely usable for any purpose." Build data minimization into your collection design from the start.
Next Steps
The right entry point depends on your current research scale:
Exploratory or under 10K requests/month: Start with a free residential proxy trial on a provider offering city-level targeting. Run the verification script above on your most problematic target domain to confirm the data quality gap firsthand before spending anything.
Regular research, 10K–500K requests/month: A bandwidth-based plan with rotating residential proxies covers most team-level market research workflows. Pair it with a lightweight scheduler (cron or Airflow) to run collection tasks during off-peak hours for better success rates on high-traffic targets.
Enterprise or multi-market concurrent monitoring: City-level targeting becomes critical at this scale. You'll need a provider with a large enough per-region IP pool to avoid reuse patterns across simultaneous campaigns, programmatic API access for session management, and clear success rate SLAs against your target domain categories.
Proxy001 supports global market research workflows with 100M+ residential IPs across 200+ regions, country and city-level geographic targeting, and direct integration with Python, Node.js, Scrapy, Puppeteer, and Selenium. If you're running into data quality issues on geo-sensitive targets — or want to benchmark residential IPs against your current setup before switching — the free trial at proxy001.com has no commitment requirement. You can verify coverage for your specific target markets, confirm the ISP ASN output, and collect a direct comparison dataset in the same session.
