








 English
English
 繁體中文
繁體中文
 Deutsch
Deutsch
 Français
Français
 Español
Español
 日本語
日本語
 Tiếng Việt
Tiếng Việt
 Português
Português
What Is Price Intelligence (And Why Your Data Layer Is the Real Bottleneck)
Price monitoring and price intelligence are not the same thing, and conflating them leads teams to invest in the wrong layer. Price monitoring is the data collection act—repeatedly fetching product prices from competitor and marketplace pages. Price intelligence is the analytical layer built on top: spotting patterns, triggering dynamic repricing rules, detecting MAP violations, and feeding demand elasticity models.
The distinction matters because most pricing failures happen at the collection layer, not the analysis layer. A sophisticated dynamic pricing engine fed incomplete or stale data will produce systematically bad recommendations. Retailers with advanced ML-based pricing systems still lose competitive edge when their crawlers get blocked on high-traffic shopping events—exactly when accurate competitor data is most valuable. Before you optimize the algorithm, you need to guarantee the data.
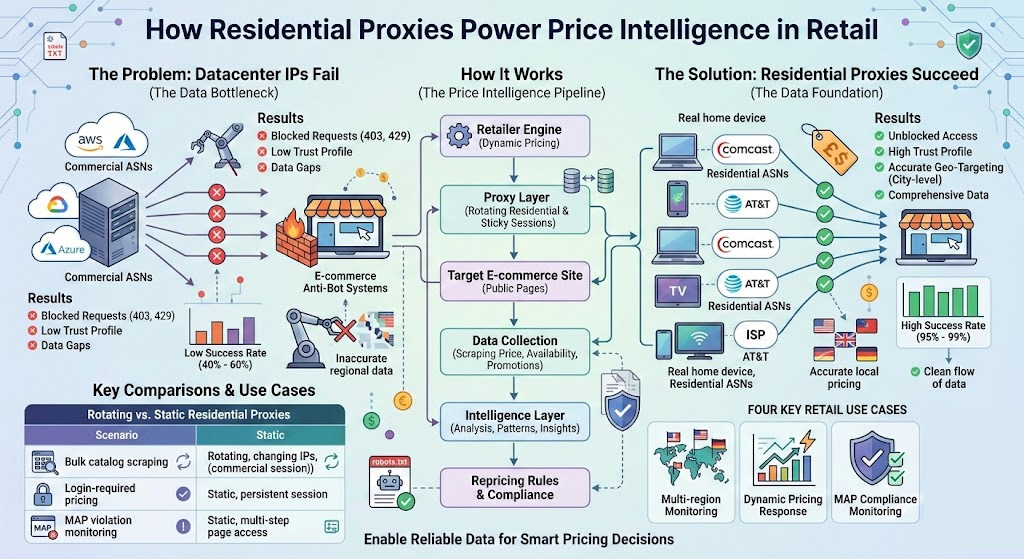
Why Residential Proxies Succeed Where Datacenter IPs Fail
The core problem with datacenter proxies for retail price monitoring isn't speed—it's trust. Anti-bot systems at major e-commerce platforms classify IPs by their Autonomous System Number (ASN). An IP block registered to a commercial cloud provider (AWS, Azure, DigitalOcean) triggers immediate suspicion, regardless of how carefully you've tuned your request headers or rotation interval. On highly protected domains, datacenter proxies see success rates drop to 40–60%, while residential proxies—assigned by ISPs to real home devices—maintain 95–99% on the same targets, because they carry a fundamentally different trust profile.
Here's what that gap actually costs at scale. If you're running 10,000 daily requests across a 5,000-SKU catalog with a 50% datacenter success rate, you're either paying double for retries or accepting a 50% data gap. Neither is compatible with a pricing operation that needs to respond to competitor moves within the hour.
The other critical advantage is geo-targeting. Many retailers and marketplaces serve different prices based on the visitor's geographic location. A request routing through a New York residential IP sees different prices than one from a Chicago or London IP—and that difference isn't cosmetic. Regional promotional pricing, currency-adjusted offers, and localized inventory levels all get obscured if your requests consistently appear to originate from a commercial server in one data center.
There's a third proxy category worth knowing before we compare: ISP proxies are datacenter-hosted IPs that have been assigned to ISP ASNs, giving them residential-level trust signals without relying on actual home devices. They're a useful middle ground when you need lower latency with moderate anti-bot bypass capability.
| Residential | Datacenter | ISP Static | |
|---|---|---|---|
| IP Trust Level | High (ISP-assigned to real devices) | Low (commercial ASN, easily flagged) | Medium-High (ISP-assigned, datacenter-hosted) |
| Success Rate on Highly Protected Sites | 95–99% | 40–60% | Higher than datacenter; varies by provider |
| Geo Precision | City-level | Region-level | City-level |
| Cost | Higher per GB | Lower per IP/month | Moderate |
| Best For | Bulk catalog scraping, geo-specific pricing | Low-security targets, internal testing | Session-based monitoring, account access |
That gap between what a server-farm IP sees and what a consumer sees plays out differently depending on your specific pricing operation. Here are the four scenarios where residential proxies directly determine data completeness.
Four Retail Use Cases Where Residential Proxies Make or Break Your Data
Multi-region price monitoring. A retailer selling in the US, UK, and Germany needs accurate local pricing data for each market—not the price Amazon shows to a request originating from a Frankfurt server farm. Residential proxies with city-level targeting let you fetch what actual consumers see, which is the only number that matters for competitive positioning. Without this, you're potentially making pricing decisions based on non-representative data.
Dynamic pricing response. The value of dynamic pricing is proportional to response latency. If a major competitor runs a flash sale, you need that signal within minutes, not hours. Flash promotions are also precisely when anti-bot defenses are most aggressive—high-traffic events attract crawlers, so platforms tighten their detection thresholds. Residential proxies sustain data access through exactly these peak periods, when datacenter proxies fail most visibly.
MAP compliance monitoring. For brand manufacturers, Minimum Advertised Price (MAP) monitoring is a legal and commercial necessity. Consumer electronics and apparel brands with multi-tier distribution networks—often hundreds of authorized resellers across Amazon, Walmart, and regional marketplaces—run continuous automated monitoring to detect violations as they occur and capture timestamped evidence for enforcement. A residential proxy infrastructure is what makes that coverage possible at scale; manual spot-checking can't keep pace with a live distribution network.
Inventory and availability tracking. Out-of-stock intelligence is often overlooked but commercially significant. When a competitor runs out of a high-demand product, that's a repricing and advertising window. Catching it requires near-real-time availability signals, which means sustained crawling of product pages—the exact workload where residential proxy reliability translates directly into revenue opportunities.
Rotating vs. Static Residential Proxies: A Decision Framework for Price Monitoring
Most guides mention that rotating and static residential proxies serve different purposes without explaining the decision logic. Here's how to actually choose.
Use rotating residential proxies for any scenario where you're making a large number of independent requests to the same domain. Scraping 50,000 product listings from a retailer's catalog, pulling search result pages, or monitoring prices across a broad SKU range all fall into this category. With rotating proxies, each request (or small batch of requests) originates from a different IP, distributing the traffic footprint across the pool and making rate-limiting or ban decisions by the target site essentially ineffective.
Use static residential proxies (sticky sessions) when your workflow requires session persistence. Accessing member-exclusive pricing, B2B portal quotes, or any page behind authentication requires maintaining cookies and session state—which is impossible with a proxy that rotates on every request. Sticky sessions hold the same IP for a configurable duration (typically 10 minutes to 24 hours), giving you the session continuity you need while still appearing as a legitimate residential user.
In practice, most production pricing stacks combine both proxy types in a tiered model from day one. Teams that start with only rotating proxies almost always add a static residential layer within a few months once they encounter login-walled pricing or marketplace seller pages that require session consistency. Building that architecture upfront is significantly less painful than retrofitting it later.
| Scenario | Proxy Type | Why |
|---|---|---|
| Bulk product catalog scraping | Rotating residential | IP rotation prevents rate-limiting across large request volumes |
| Login-required pricing (B2B portals, member prices) | Static residential (sticky session) | Session cookies require IP consistency |
| Search result price monitoring (Google Shopping, Bing) | Rotating residential | Each query is stateless |
| MAP violation screenshot capture (evidence for enforcement) | Static residential | Consistent session for multi-step page navigation |
| Competitor flash sale detection | Rotating residential | High-frequency, stateless page checks |
| Marketplace seller account price monitoring | Static residential | Account session persistence required |
A Minimal Architecture for Proxy-Powered Price Intelligence
If your team prefers a managed approach without writing a scraping layer, most residential proxy providers offer structured APIs that return pricing data directly—worth checking with your shortlisted vendor before building a custom pipeline. The architecture below is for teams building their own.
Prerequisites before you start:
Python 3.9+ with
requests,beautifulsoup4, andcsvinstalledA residential proxy plan with rotating support and valid credentials
Critical pre-check: Right-click the target product page → View Page Source → search for the actual price value (e.g., "29.99"). If it appears in the raw HTML, the
requests-based approach below will work. If it doesn't appear, the site renders prices via JavaScript—skip to the Troubleshooting section before writing any code.robots.txt reviewed for the target domain (
https://domain.com/robots.txt); if it disallows the paths you're crawling, use the site's official data API or partner program instead
The four-layer pipeline:
Layer 1 — Proxy Layer. Configure your rotating residential proxy as the egress point for all outbound requests. The standard integration uses an HTTP/HTTPS proxy URL with credentials:
import requests
from bs4 import BeautifulSoup
import csv
from datetime import datetime, timezone
# Credentials from your proxy provider dashboard
PROXY_HOST = "your-proxy-endpoint.example.com"
PROXY_PORT = "8080"
PROXY_USER = "your_username"
PROXY_PASS = "your_password"
proxies = {
"http": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}",
"https": f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}",
}
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/122.0.0.0 Safari/537.36"
),
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
}Note on geo-targeting: If your provider supports geographic targeting, it's typically configured via session parameters in the username field (e.g., a country suffix). The exact format varies by provider—check your proxy provider's dashboard under API Docs or Session Parameters for the correct syntax. To verify geo-targeting is working, route a request to https://ipinfo.io/json through the proxy and confirm the country field matches your target region.
Layer 2 — Scraping Layer. Issue requests through the proxy and parse the HTML for price elements. Inspect the page source to identify the right CSS selector for your target site before scaling:
def scrape_price(url: str, geo_label: str = "us") -> dict:
"""
Scrapes the displayed price from a product URL.
geo_label: a string tag for your own records (e.g. "us", "uk")
"""
try:
resp = requests.get(url, proxies=proxies, headers=headers, timeout=30)
resp.raise_for_status()
soup = BeautifulSoup(resp.text, "html.parser")
# Adjust this selector to match your target site.
# Always verify against the current page source — site structures change.
# Example patterns: .a-price-whole (Amazon, verify current structure
# by inspecting /dp/ page source), [data-price], .price
price_elem = soup.select_one(".a-price-whole, [data-price], .price")
price_text = price_elem.get_text(strip=True) if price_elem else "NOT_FOUND"
return {
"url": url,
"price": price_text,
"geo": geo_label,
"http_status": resp.status_code,
"scraped_at": datetime.now(timezone.utc).isoformat(),
}
except requests.exceptions.RequestException as exc:
return {"url": url, "price": "ERROR", "error": str(exc),
"scraped_at": datetime.now(timezone.utc).isoformat()}Layer 3 — Data Layer. Write results to a structured store. For initial builds, a timestamped CSV is sufficient. Production deployments typically write to PostgreSQL or a time-series database to enable trend queries and alert triggers:
TARGET_URLS = [
{"url": "https://example-retailer.com/product/widget-pro-x", "geo": "us"},
{"url": "https://example-retailer.com/product/widget-pro-x", "geo": "gb"},
]
OUTPUT_FILE = "price_data.csv"
FIELDNAMES = ["url", "price", "geo", "http_status", "scraped_at"]
with open(OUTPUT_FILE, "a", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=FIELDNAMES, extrasaction="ignore")
writer.writeheader()
for target in TARGET_URLS:
row = scrape_price(target["url"], geo_label=target["geo"])
writer.writerow(row)
print(f"[{row['scraped_at']}] {row.get('price','ERROR')} — {target['url']} ({target['geo']})")Layer 4 — Intelligence Layer. The pipeline above produces a time-stamped price series per SKU per geo. From here, your pricing system queries for changes exceeding a defined threshold (e.g., >5% drop in 2 hours), triggers repricing rules, or fires a webhook alert to your merchandising team. This integration is specific to your existing pricing stack—most dynamic pricing platforms expose an inbound API for competitive price signals.
Verification checkpoints:
You receive HTTP 200 responses (not 403 or 429)
The
pricefield contains actual price text, not "NOT_FOUND"Multi-geo runs return different price values for the same SKU (confirms geo-targeting is working)
Three common failure modes and how to fix them:
| Symptom | Likely Cause | Fix |
|---|---|---|
| Consistent 403 responses | Proxy type flagged; headers too sparse | Verify residential proxy credentials are active; add Referer and Accept-Encoding headers |
price = "NOT_FOUND" on all records | Target renders prices via JavaScript; static HTML scraping won't work | Switch to Playwright with proxy integration (see below) |
| Frequent CAPTCHA responses | Request frequency exceeds the site's load tolerance | Reduce request frequency to respect the site's load limits; use sticky sessions to maintain session state without requiring repeated rapid re-access |
If you hit the JS rendering failure: The requests + BeautifulSoup approach won't work for JavaScript-rendered prices. Replace the scrape_price() function with a Playwright-based equivalent. Install with pip install playwright && playwright install chromium, then pass proxy credentials through the browser context:
from playwright.sync_api import sync_playwright
def scrape_price_js(url: str, geo_label: str = "us") -> dict:
with sync_playwright() as p:
browser = p.chromium.launch(
proxy={
"server": f"http://{PROXY_HOST}:{PROXY_PORT}",
"username": PROXY_USER,
"password": PROXY_PASS,
},
headless=True,
)
page = browser.new_page()
page.goto(url, timeout=30000)
page.wait_for_timeout(2000) # allow JS to render
# Adjust selector to match target site's current price container
price_elem = page.locator(".a-price-whole, [data-price], .price").first
price_text = price_elem.inner_text() if price_elem.count() > 0 else "NOT_FOUND"
browser.close()
return {
"url": url,
"price": price_text,
"geo": geo_label,
"scraped_at": datetime.now(timezone.utc).isoformat(),
}Compliance note before scaling: The architecture above is technically operational in hours. But which domains you run it against requires a separate review. Before scaling beyond your initial test targets, read Section 7 on compliance—specifically the robots.txt directives and ToS review steps. Catching a policy issue before you've scraped millions of pages is significantly less costly than addressing it afterward.
What to Look for in a Residential Proxy Provider (Specifically for Price Intelligence)
Generic proxy comparison guides rank providers on features that don't necessarily matter for price intelligence workloads. Here's what does:
| Evaluation Dimension | Why It Matters for Price Intelligence | Minimum Viable Threshold |
|---|---|---|
| IP Pool Size | Larger pools reduce the likelihood of IP reuse on the same target domain during high-volume scraping—a key factor in maintaining consistent success rates | 50M+ IPs |
| Geo Precision | City-level targeting required to capture localized pricing; region-level is insufficient for multi-market monitoring | City-level coverage in your target markets |
| Session Control | Must support both rotating (bulk catalog) and sticky sessions (login-based targets) on the same plan | Both modes configurable |
| Success Rate SLA | Directly determines data completeness; a 10% success rate gap means 10% missing price coverage | >95% on protected domains |
| SDK / API Integration | Python and headless browser support (Puppeteer, Playwright, Selenium) required for most scraping stacks | Native Python and JS SDK |
| Free Trial / Test Credits | Validate compatibility with your specific target sites before committing to a volume plan | Available without upfront purchase |
For teams building or scaling a price intelligence operation, Proxy001 covers each of these requirements. The network spans 100M+ residential IPs across 200+ regions with city-level geo-targeting, supports both rotating and sticky sessions on the same plan, and integrates natively with Python, Node.js, Puppeteer, and Selenium. Their free trial lets you run actual requests against your real target sites before any purchasing commitment—which is the only meaningful way to validate proxy performance for your specific use case.
Legal and Compliance Lines Every Retail Intelligence Team Must Know
This isn't boilerplate. B2B teams need legal sign-off before deploying automated price collection at scale, and the legal landscape has actually clarified favorably over the past two years.
Public data vs. authenticated access. The most important boundary is whether you're accessing data that requires authentication. The January 2024 ruling in Meta v. Bright Data established that logged-off scraping of publicly available data—pages accessible to any anonymous visitor—does not constitute a breach of platform Terms of Service under the contract law framework the court applied. The ruling was specific to public data; anything behind a login wall is a different legal question. For retail price intelligence, this is largely favorable: product prices, availability, and promotional information displayed on public-facing pages fall squarely in the protected category.
robots.txt and Terms of Service. robots.txt is not legally binding in the US, but courts have started treating disregard for it as evidence of bad faith in ToS disputes. Check it at https://domain.com/robots.txt and review the Disallow directives for the paths you plan to crawl. Many e-commerce platforms prohibit automated access explicitly in their ToS—which doesn't automatically make scraping illegal, but does expose you to breach-of-contract claims in some jurisdictions. Before deploying at scale, have your legal team review the ToS of your top 10 target domains.
GDPR and data minimization. If you're operating in or targeting EU markets, GDPR's data minimization principle applies to what you store. Product prices and availability signals are legitimate business intelligence. User identifiers, behavioral data, or any information tied to individual consumers is off-limits. Keep your scraping scope narrow: prices, product titles, availability flags, and promotional labels only.
Operational governance checklist for internal compliance:
Maintain a documented list of approved target domains with rationale
Set and enforce request rate limits (aggressive crawling that degrades site performance crosses into potential CFAA territory in the US)
Define data retention periods—raw HTML captures beyond 90 days rarely have analytical value and increase legal exposure
Log request metadata for auditability: timestamps, target URLs, IP geo, HTTP response codes
Designate a legal review checkpoint before adding any target that requires login-based access
Next Steps
If you're evaluating residential proxies for price intelligence, here's how to move from evaluation to production efficiently:
Map your use cases to proxy types first. Use the rotating vs. static framework from Section 4 to decide your architecture before you buy. Getting this wrong means rebuilding the integration layer later.
Test against real targets before committing to a volume plan. Request a free trial from your shortlisted provider and run it against the three or four domains that represent your most challenging scraping targets—not easy ones. Success rate on your actual targets is the only metric that matters.
Run your legal checklist before scale-out. The pipeline in Section 5 can be operational in hours. The compliance review takes longer, but catching a ToS issue before you've scraped 10 million pages is significantly less costly than catching it after.
Start validating with Proxy001
The fastest way to know whether a proxy network will work for your specific targets is to test it against those targets—not a vendor benchmark. Proxy001 offers a free trial with no upfront commitment, so you can run your actual target URLs through a 100M+ residential IP network spanning 200+ regions and see real success rates before signing anything. The integration takes under 30 minutes if you're using Python or Node.js; Puppeteer and Selenium are natively supported if you need headless browser rendering. Start at proxy001.com.
